

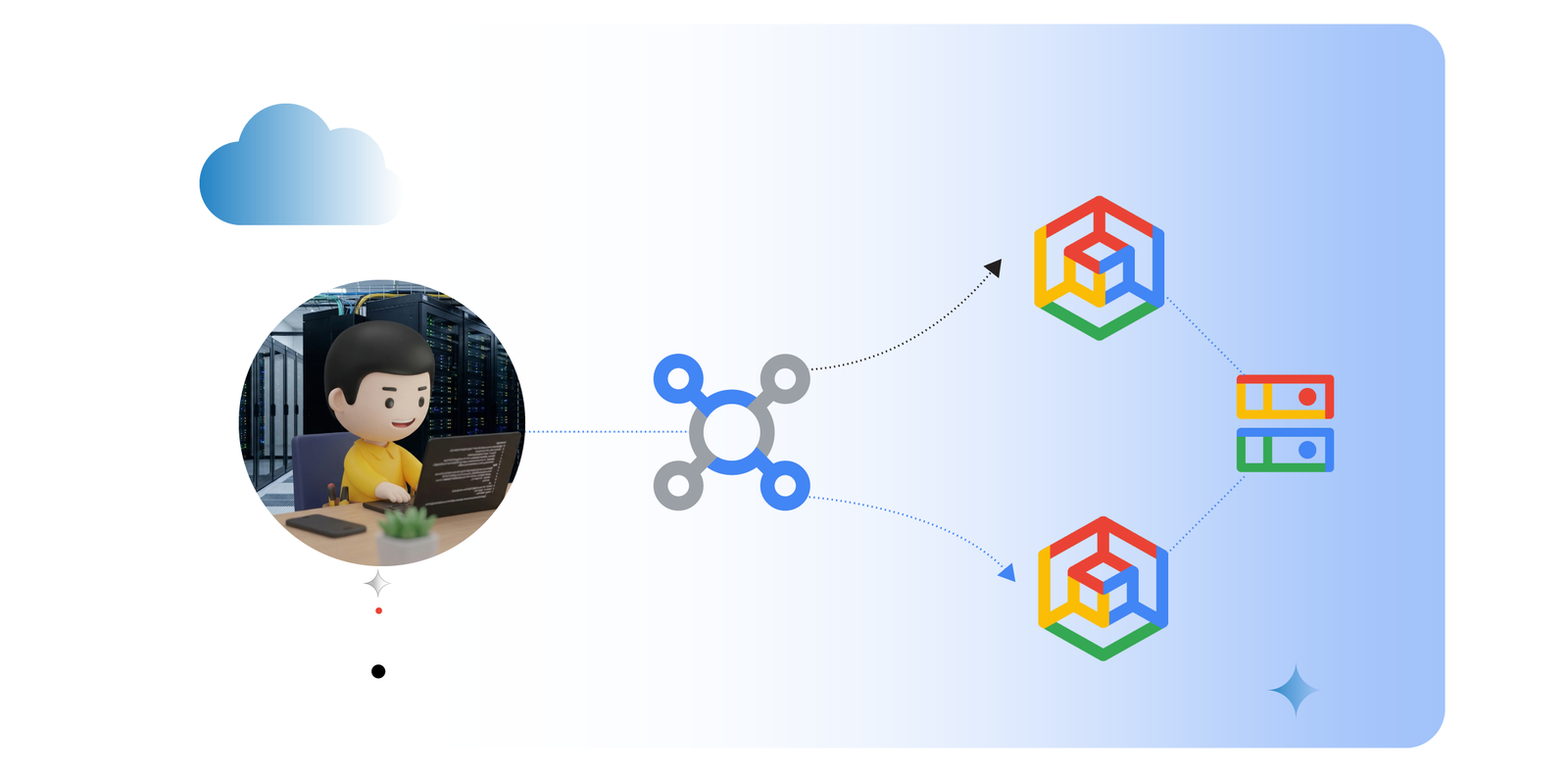
What happens when your workload fails in one region but you need access to service? This is a common case for availability and uptime. With recent enhancement to the Kubernetes ecosystem and capabilities like Dynamic Resource Allocation (DRA) and Inference Gateway. I decided to experiment with these capabilities in Google Cloud for a simple test using an AI inference workload.
In this blog, we will explore this setup and you can also jump straight into the detailed configs in this codelab Build multi-cluster GKE Inference Gateway, with TPUs , Cloud Storage FUSE and managed DRANET.
Building blocks
To build out this experiment, use the following products, features, and tools:
-
Google Kubernetes Engine (GKE) managed DRANET: This is a managed feature that lets you request and share resources among Pods. This supports GPUs, and TPUs. In this test TPUs were used in two different regions with networking assigned using managed DRANET.
-
Multi-cluster GKE Inference gateway: Load balances your AI/ML inference workloads across multiple GKE clusters. This works in a failover situation which is what my experiment intended to test. The type which supports this is the Multi-cluster Cross-region internal Application Load Balancer gke-l7-cross-regional-internal-managed-mc
-
Cloud Storage FUSE: Provides a way to store data, models, checkpoints, and logs directly in Cloud Storage. To speed up the deployment, an open source gemma model was downloaded to this storage for retrieval.
-
Virtual private Cloud (VPC): The foundational global network providing isolated, secure communication for the internal load balancers and compute nodes
-
GKE Fleets: Fleets group the separate regional clusters under a unified management control plane
-
TPU v6e: Google’s custom AI accelerators that provide the high-performance compute required to serve the model. The VM family type used was the ct6e-standard-4t in a 2×2 Slice
Design pattern example
The aim is to deploy a LLM model (Gemma 3) onto 2 GKE clusters in different regions. Each cluster will use 4 TPU v6e chips. The model should be stored in Cloud Storage. The workload is served using GKE Inference Gateway which supports multi-clusters. The traffic should be routed to the region closest to the user and failover to the other region if one region fails.






{kind=link}