


As AI workloads transition from experimental prototypes to production-grade services, the infrastructure supporting them faces a growing utilization gap. Enterprises today typically face a binary choice: build for high-concurrency, low-latency real-time requests, or optimize for high-throughput, “async” processing.
In Kubernetes environments, these requirements are traditionally handled by separate, siloed GPU and TPU accelerator clusters. Real-time traffic is over-provisioned to handle bursts, which can lead to significant idle capacity during off-peak hours. Meanwhile, async tasks are often relegated to secondary clusters, resulting in complex software stacks and fragmented resource management.
For AI serving workloads, Google Kubernetes Engine (GKE) addresses this “cost vs. performance” trade-off with a unified platform for the full spectrum of inference patterns: GKE Inference Gateway. By leveraging an OSS-first approach, we’ve developed a stack that treats accelerator capacity as a single, fluid resource pool that can serve workloads that require serving both deterministic latency and high throughput.
In this post, we explore the two primary inference patterns that drive modern AI services and the problems and current solutions available for each. By the end of this blog, you will see how GKE supports these patterns via GKE Inference Gateway.
Two inference patterns: Real-time and async
We will cover two types of AI inference workloads in this blog: real-time and async. For real-time inference, these are high-priority, synchronous requests—such as a chatbot interaction where a customer is waiting for an immediate response from an LLM. In contrast, async traffic, such as documenting indexing or product categorization in retail is typically latency-tolerant, meaning the traffic is often queued and processed with a delay.
1. Real-time inference: 0 second latency-sensitive requests
For high-priority, synchronous traffic, latency is the most critical metric. However, traditional load balancing often ignores accelerator-specific metrics like KV cache utilization that indicate high latency, leading to suboptimal performance.
The solution: GKE Inference Gateway
The solution for this problem is Inference Gateway, which performs latency-aware scheduling by predicting model server performance based on real-time metrics (e.g., KV cache status), minimizing time-to-first-token. This also reduces queuing delays and helps ensure consistent performance even under heavy load.
2. Async (near-real time) inference: 0 minute latency
Latency-tolerant tasks operate with minute-scale service-level objectives (SLOs) rather than millisecond requirements. In a traditional setup, teams often run these requests on separate, dedicated infrastructure to prevent resource contention with real-time traffic. This static partitioning can lead to fragmented utilization and inflated hardware costs. Furthermore, custom-built async pollers typically lack the sophisticated scheduling logic required to multiplex workloads onto the same accelerators, forcing engineers to manage two disparate and complex software stacks.
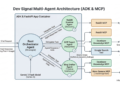
The solution : The Async Processor Agent + Inference Gateway
A “plug-and-play” architecture that integrates Inference Gateway with Cloud Pub/Sub. A Batch Processing Agent pulls requests from configured Topics and routes them to the Inference Gateway as “sheddable” traffic. The system treats batch tasks as “filler,” using idle accelerator (GPU/TPU) capacity between real-time spikes. This minimizes resource fragmentation and helps reduce hardware costs.
Key capabilities:
-
Support for real-time traffic: Real-time inference traffic is handled by Inference Gateway
-
Persistent messaging: Reliable request handling occurs via Pub/Sub.
-
Intelligent retries: Leverage the configurable retry logic built into the queue architecture based on real-time monitoring of the queue depth.
-
Strict priority: Real-time traffic always takes precedence over batch traffic at the gateway level.
- Tight integration: Users simply “plug in” a Pub/Sub topic; the agent handles the routing logic to the shared accelerator pool.





{kind=link}