

1. Schema Ontology
Schema ontology is about understanding your database structure and semantics. This includes natural language descriptions of tables and columns. The QueryData LLM has a greater chance to translate the natural language question into the correct query using these instructions. You can think of schema ontology as a set of “cues” or “hints” – meant to steer the LLM into picking the right tables and columns and synthesizing them correctly into a database query. A couple of examples:
Here is what a database-level description could look like for a search engine of real estate listings:
“Listings, real estate agents and information about communities where listings are located – schools, amenities and hazards: fire, flood and noise”
The table description for property could look like this:
“Current real estate listing, including houses, townhomes, condos and land”
An example of column description that explains that the proximity_miles means
“property distance from the district’s school in miles”
For ease of use, you can autogenerate rich descriptions, which will typically include sample values of the column.
2. Query Blueprints
If ontology is the vocabulary, query blueprints are the way to introduce fine control of the generated SQL for important questions that must absolutely receive accurate and business-relevant answers. For example, consider the question “Riverside houses close to good schools”. The interpretation of “close” and “good” provided by Gemini is impressive- in a demo application it translated to
…
WHERE city_name = ‘Riverside’ AND school_ranking <= 5
ORDER BY proximity_miles ASC
But this interpretation still leaves much to be desired: Wouldn’t you drive one more mile for a school whose school_ranking is much higher than the Gemini-chosen cutoff? Of course you would! Both proximity and school ranking should affect the overall ranking. A no-cut-corners developer will take control of the interpretation of “close to good school” by introducing a sophisticated ranking function, which may be the result of continuous A/B experiments, along with sensible cutoffs.
Templates
In particular, she will use a template: A pair of natural language intent with its respective parameterized SQL translation.
parameterized_intent : “$1 houses close to good schools”,
parameterized_SQL : “SELECT … FROM …
WHERE city_name = $1 AND “school_ranking” <= 5 AND "proximity_miles" <= 2
ORDER BY school_score(“school_ranking”, “proximity_miles”)”
– the school_score stored procedure combines school ranking and proximity into a single ranking
Such info can be given in a JSON file but, even more user-friendly, you can use Gemini CLI, prompt it with an example natural language question and your ideal respective SQL and it will produce the JSON for you.
Furthermore, templates enable the agent to explain how the question was interpreted. This mitigates the effect of the occasional remaining inaccuracies, allowing a human-in-the-loop or agent to understand what the answer of QueryData means.
Facets
While plain query templates provide highly accurate and explainable answers, they have low flexibility: they can only answer the specific critical question patterns that they were designed for. What if you wanted to combine the “close to good schools” with price conditions, square footage, bedroom conditions and more. The facets generalize templates to combine the best of both worlds: highly-accurate, explainable answers to large numbers of questions.
“parameterized_intent”: “Property price between $1 and $2”, “parameterized_sql_snippet”: “T.”price” BETWEEN $1 AND $2″
Value searches
Some ambiguities in the NL question are rooted deep in the private data of your database and need a collaboration of the LLM with the database to disambiguate. Value searches solve the hard problem of correctly associating data values in the database with the “entities” that the question talks about.
For example, consider the question “Westwod”s sold properties in the last 1 month.” The first problem is that there is no “Westwod”; it is a misspelling of “Westwood”. Apart from the misspelling, there is a second problem – a deeper ambiguity in our sample database: “Westwood” appears as both the name of a real estate brokerage and as the name of a city. Value searches can utilize the built-in powerful vector+text search capabilities of Google Cloud’s AI-native databases. Here, value searches will enable QueryData to respond to the agent that this is likely a misspelling of ‘“westwood, which appears as both a real estate brokerage and a city name.
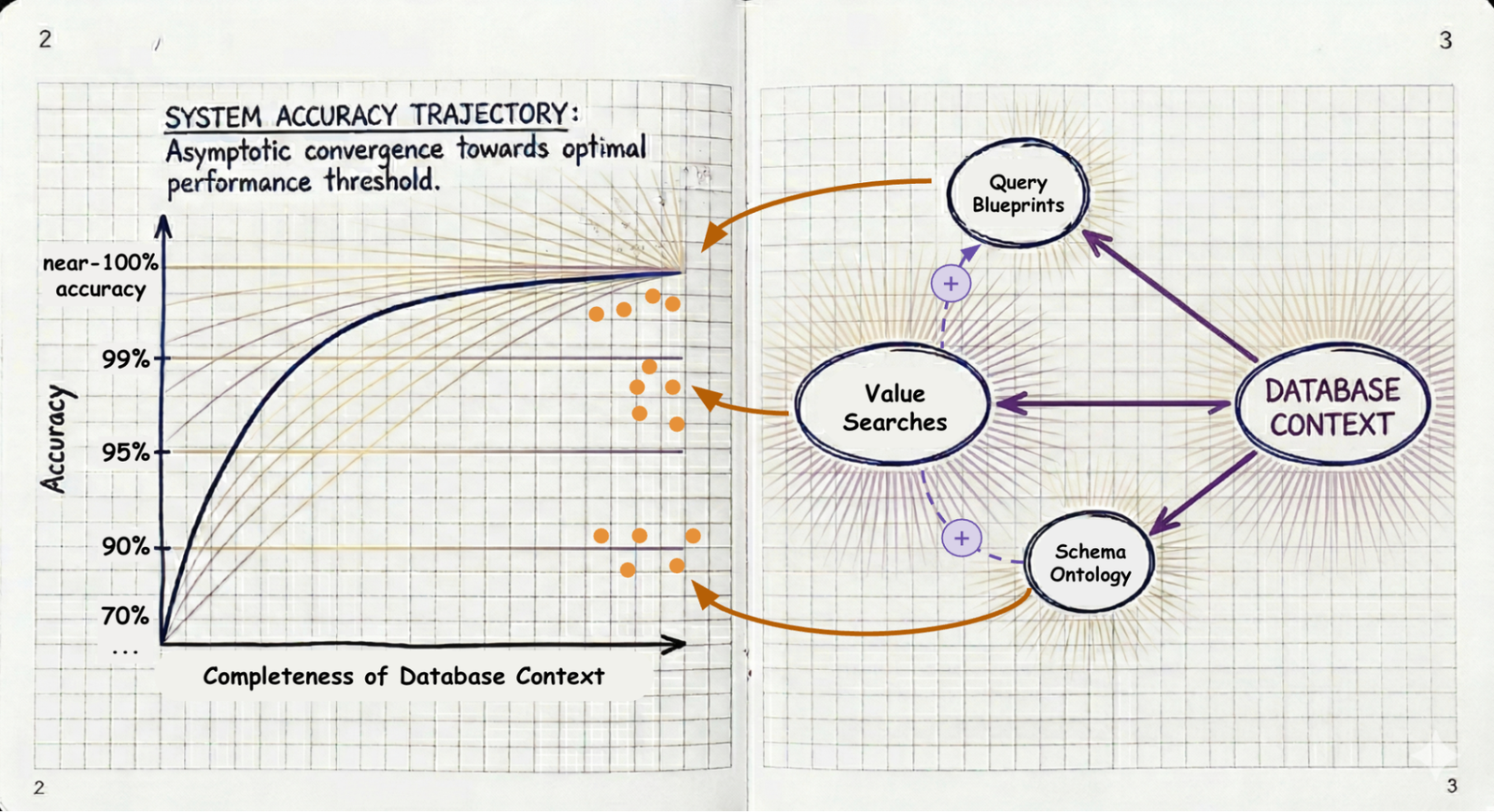
Accuracy As Foundation for Agentic Actions
Agentic workflows are poised to revolutionize operations, but they are unforgiving when it comes to accuracy. Through context engineering, businesses can mitigate compounding failures and start trusting their autonomous agents to deliver.
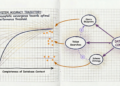
As a next step, you can explore how to create context sets across these databases:
And here – your “cheat sheet” for building blocks of context (courtesy by Nanobanana):






{kind=link}