

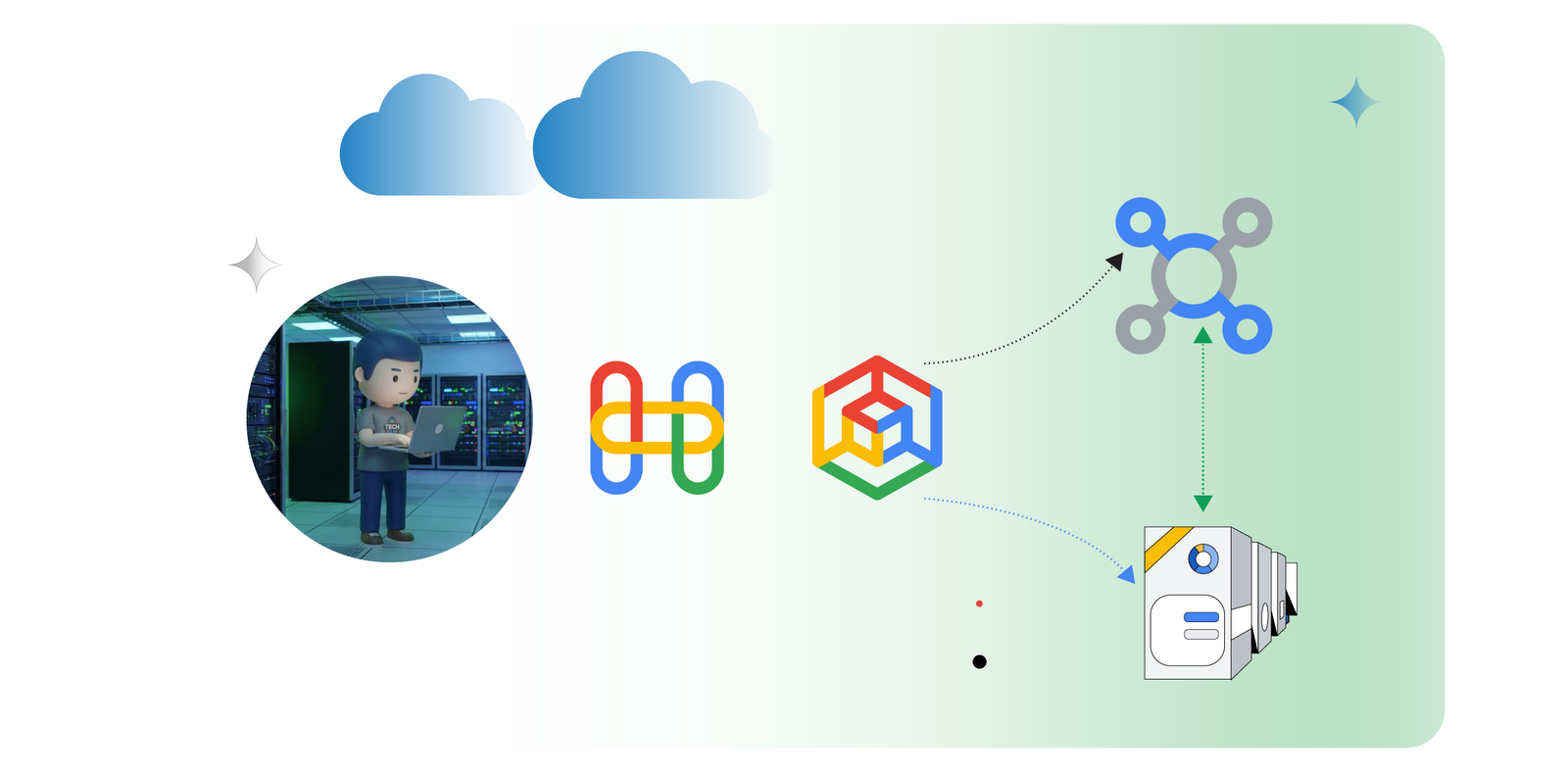
Building and serving models on infrastructure is a strong use case for businesses. In Google Cloud, you have the ability to design your AI infrastructure to suit your workloads. Recently, I experimented with Google Kubernetes Engine (GKE) managed DRANET while deploying a model for inference with NVIDIA B200 GPUs on GKE. In this blog, we will explore this setup in easy to follow steps.
What is DRANET
Dynamic Resource Allocation (DRA) is a feature that lets you request and share resources among Pods. DRANET allows you to request and allocate networking resources for your Pods, including network interfaces that support TPUs & Remote Direct Memory Access (RDMA). In my case, the use of high-end GPUs.
How GPU RDMA VPC works
The RDMA network is set up as an isolated VPC, which is regional and assigned a network profile type. In this case, the network profile type is RoCEv2. This VPC is dedicated for GPU-to-GPU communication. The GPU VM families have RDMA capable NICs that connect to the RDMA VPC. The GPUs communicate between multiple nodes via this low latency, high speed rail aligned setup.
Design pattern example
Our aim was to deploy a LLM model (Deepseek) onto a GKE cluster with A4 nodes that support 8 B200 GPUs and serve it via GKE Inference gateway privately. To set up an AI Hypercomputer GKE cluster, you can use the Cluster Toolkit, but in my case, I wanted to test the GKE managed DRANET dynamic setup of the networking that supports RDMA for the GPU communication.






{kind=link}