

5. Speculative decoding
Remember: during the decode phase, tensor cores are mostly idle because there’s a bottleneck on memory bandwidth. Speculative decoding exploits this wasted computation power.
A small, fast “draft” model generates several candidate tokens cheaply. The large target model then verifies all of the candidates in a single forward pass, which is a parallel compute-bound operation, rather than a sequential memory-bound one. If the draft model predicted the candidates correctly, you’ve generated 4-5 tokens for the memory cost of one.
This approach directly breaks the TBT floor set by memory bandwidth. If you’re not using speculative decoding for latency-sensitive workloads, you’re not leveraging one of the most impactful optimizations available.
Although the addition of a draft model can introduce some operational complexity and slightly increase compute costs, the draft model is relatively tiny compared to the main model. This tradeoff for latency is worthwhile.
Note that some newer models have introduced self-speculative decoding, which eliminates the overhead of managing a second model. These models use specialized internal layers (often called prediction heads) that are trained to predict extra future tokens simultaneously. These models generally achieve a highly meaningful token hit rate.
Case study: How Vertex AI moved closer to the frontier
The Vertex AI engineering team moved closer to the frontier when they adopted GKE Inference Gateway, which is built on the standard Kubernetes Gateway API. Inference Gateway intercepted requests at Layer 7 and added two critical layers of intelligence:
-
Load-aware routing: It scraped real-time metrics (like KV cache utilization and queue depth) directly from the model server’s Prometheus endpoints. This process routes requests to the pod that can serve them the fastest.
-
Content-aware routing: Crucially, it inspected request prefixes and routed traffic to the pod that already held that specific context in its KV cache. This process avoids expensive re-computation.
When the production workloads were migrated to this intelligent routing architecture, the Vertex AI team proved that optimizing the network layer is key to unlocking performance at scale. Validated on production traffic, the results were stark:
-
35% faster TTFT for Qwen3-Coder (context-heavy coding agent workloads)
-
2x better P95 tail latency (52% improvement) for DeepSeek V3.1 (bursty chat workloads)
-
Doubled prefix cache hit rate (optimized from 35% to 70%)
The bottom line
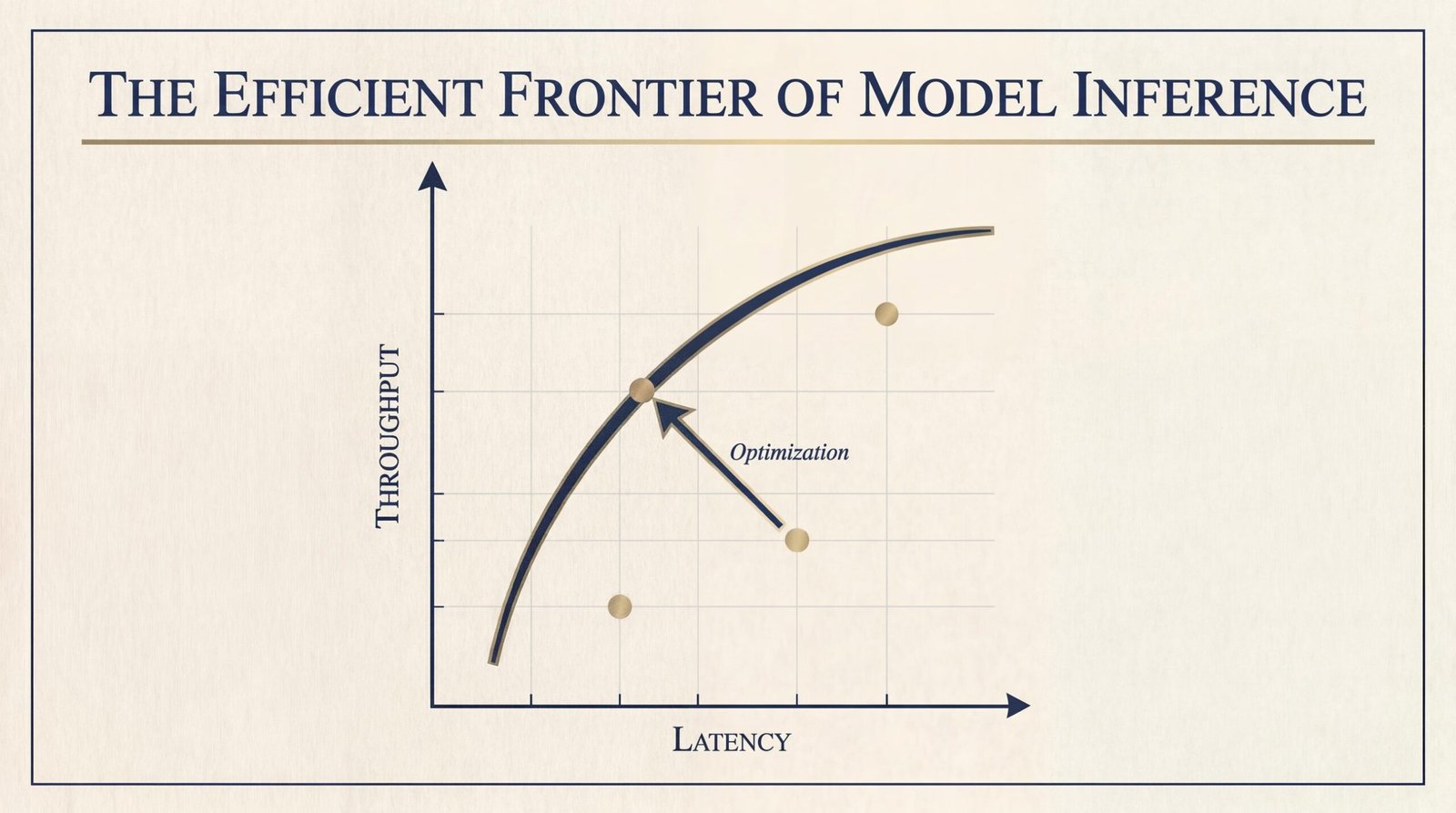
LLM inference has an efficient frontier, which represents a hard boundary where latency and throughput are optimally balanced for a given compute budget.
Getting to that frontier is within your control. The techniques exist today: continuous batching, paged attention, intelligent L7 routing, speculative decoding, quantization, and prefill and decode disaggregation. The GKE Inference Gateway case study shows that routing alone, without changing hardware, models, or cluster size, cut TTFT by 35% and doubled cache efficiency. If you’re not applying the full stack, you’re operating below the curve and overpaying for every token.
The frontier itself keeps moving outward. This part is outside of your control. Researchers publish new algorithms, hardware vendors ship new architectures, and open-source serving frameworks integrate these algorithms and architectures. Something that was cutting-edge optimization 18 months ago became a baseline table stake. Your job isn’t to predict which breakthrough comes next; it’s to build infrastructure flexible enough to absorb it when it arrives.
The organizations that will win on inference economics aren’t the ones with the most GPUs. They’re the ones that systematically close the gap to today’s frontier while they stay ready for tomorrow’s.
Have you applied any of these optimization techniques to your own LLM inference workloads? I’d love to hear about your experience! Share what you’ve built with me on LinkedIn, X, or Bluesky!







{kind=link}